Frequently, analysts or evaluators gather information of workers, children, programs, participants and so on, and subsequently realize that information is missing on some important variables for several respondents in the sample. For example, in a survey we have administered to artists in communities around the country, some artists choose not to report their interests in specific services or income level. Missing data is an issue in nearly every study, and the evaluator has to decide which methods are the most appropriate for dealing with this complex issue.
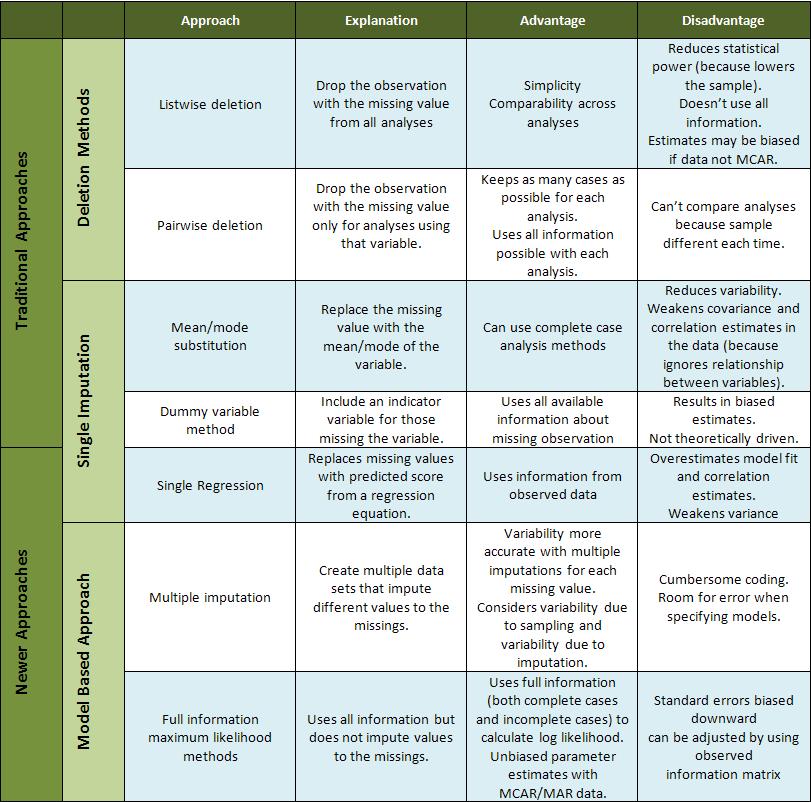
In this context, it is essential to first understand the nature of the data in order to identify potential problems such as attrition, skip patterns or random data collection issues. Once the overall data set is understood, it is necessary to check the missing data patterns in order to see if certain groups or certain responses are more likely to have missing values. These will help the evaluator to identify if the missing data is: missing completely at random (MCAR), missing at random (MAR) or missing not at random (MNAR). If the data is MCAR, we can simply delete these observations, as the estimation process will not be biased or inconsistent, though there may be some loss of precision due to a smaller sample. However, missing data is more problematic when it occurs in a nonrandom sample. In these situations the only way to obtain an unbiased estimation of the statistics is to use a procedure that accounts for the missing data. Thus, it is important to acknowledge that the consequence of missing observations is going to be contingent on the assumptions about the mechanism behind the missing information. The following table represents a brief description of some methods for dealing with missing values, as well as the advantages and disadvantages of each approach.
Strong introductory readings for this topic include: Afifi, A. A., & Elashoff, R. M. (1966). Missing observations in multivariate statistics I. Review of the literature. Journal of the American Statistical Association, 61(315), 595-604. Acock, A. (2005). Working with Missing Values. Journal of Marriage and the Family, 67 (November): 1012-1028. Graham, J. W. (2009). Missing data analysis: Making it work in the real world. Annual review of psychology, 60, 549-576. Pigott, T. (2001). A Review of Methods for Missing Data. Educational Research and Evaluation, Vol. 7, No. 4, pp. 353-383. Schafer, J. L., & Graham, J. W. (2002). Missing data: Our view of the state of the art. Psychological methods, 7(2), 147-177. Scheffer, J. (2002). Dealing with missing data. Research letters in the information and mathematical sciences, 3(1), 153-160.
Strong introductory readings for this topic include: Afifi, A. A., & Elashoff, R. M. (1966). Missing observations in multivariate statistics I. Review of the literature. Journal of the American Statistical Association, 61(315), 595-604. Acock, A. (2005). Working with Missing Values. Journal of Marriage and the Family, 67 (November): 1012-1028. Graham, J. W. (2009). Missing data analysis: Making it work in the real world. Annual review of psychology, 60, 549-576. Pigott, T. (2001). A Review of Methods for Missing Data. Educational Research and Evaluation, Vol. 7, No. 4, pp. 353-383. Schafer, J. L., & Graham, J. W. (2002). Missing data: Our view of the state of the art. Psychological methods, 7(2), 147-177. Scheffer, J. (2002). Dealing with missing data. Research letters in the information and mathematical sciences, 3(1), 153-160.